






摘要:本文介绍了如何使用Python实时爬取页面验证码的技术解析与操作指南。文章详细阐述了验证码爬取的原理和步骤,包括如何识别验证码类型、使用Python库进行抓取、处理反爬虫机制等。本文旨在为开发者提供实用的指导,帮助他们在12月期间成功实现验证码的实时爬取,提高爬虫效率和成功率。
随着互联网技术的飞速发展,网络爬虫技术也日新月异,在自动化处理网页数据时,验证码的实时爬取成为一项重要技能,本文将重点讨论如何使用Python进行页面验证码的实时爬取,特别是在12月这个特殊时期可能遇到的挑战和应对策略,本文旨在提供一个全面的指南,帮助读者理解并实现验证码爬取技术。
要点一:验证码爬取的重要性与挑战
验证码作为一种安全机制,广泛应用于网站登录、表单提交等场景,实时爬取验证码对于自动化处理任务至关重要,验证码的爬取面临诸多挑战:
1、验证码种类繁多:验证码形式多样化,包括文字、图片、语音、视频等,每种形式的验证码都有其独特的识别难点。
2、验证码反爬机制:网站为防止爬虫攻击,会采取各种反爬措施,如动态加载、加密传输等,增加了爬取的难度。
3、法律与道德约束:在爬虫过程中,必须遵守相关法律法规和网站的使用协议,避免侵犯他人权益。
要点二:Python在验证码爬取中的应用
Python作为一种强大的编程语言,广泛应用于网络爬虫领域,在验证码爬取过程中,我们可以借助Python的第三方库来实现功能,以下是几个常用的库:
1、Selenium:一个用于自动化Web应用程序的库,可以模拟浏览器行为,实现验证码的自动获取。

2、OpenCV:一个开源计算机视觉库,可以处理图像验证码,通过图像处理和机器学习技术识别验证码。
3、PyAutoGUI:一个用于编程控制鼠标和键盘的库,结合Selenium使用,可以实现验证码的自动输入。
要点三:实时爬取验证码的技术实现
实时爬取验证码需要综合运用Python的各种技术和库,以下是一个基本的实现流程:
1、环境搭建:安装Python和相关库,如Selenium、OpenCV等。
2、浏览器模拟:使用Selenium启动浏览器实例,并访问目标网页。
3、验证码定位:通过Selenium的定位功能,找到网页中的验证码图片或语音等。
4、验证码识别:根据验证码类型选择合适的方法进行识别,对于图片验证码,可以使用OpenCV进行图像处理;对于语音或视频验证码,则需要更复杂的语音识别和视频处理技术。
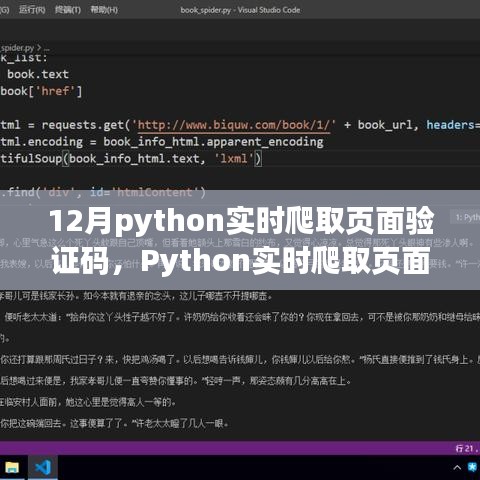
5、验证信息提交:将识别到的验证码信息提交到目标网站,完成自动化操作。
在实现过程中,需要注意以下几点:
1、动态加载与加密传输的处理:针对网站的反爬机制,需要采用相应的方法处理动态加载和加密传输的问题,可以使用Selenium的等待机制处理动态加载,使用解密算法处理加密传输的数据。
2、法律与道德约束遵守:在进行爬虫操作时,必须遵守相关法律法规和网站的使用协议,尊重他人隐私和权益,避免侵犯他人知识产权或进行恶意攻击等行为。
3、技术更新与跟进:随着网站反爬技术的升级,爬虫技术也需要不断更新和改进,关注最新的技术动态和研究成果,以便更好地应对挑战。
本文介绍了Python在实时爬取页面验证码方面的应用和技术实现,通过理解验证码爬取的重要性与挑战、应用Python相关库以及掌握实时爬取验证码的技术实现流程,读者可以更好地应对自动化处理任务中的验证码问题,随着技术的不断发展,我们将继续关注验证码反爬技术的最新动态,为自动化处理任务提供更多有效的解决方案。
转载请注明来自上海嘉贶文化传播有限公司,本文标题:《Python实时爬取页面验证码技术解析与操作指南》







 蜀ICP备2022005971号-1
蜀ICP备2022005971号-1
还没有评论,来说两句吧...